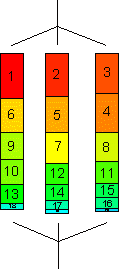
inner loops get smaller ("triangular matrix")
unbalanced distribution of workload
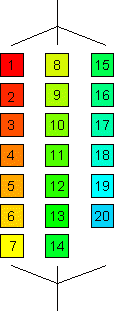
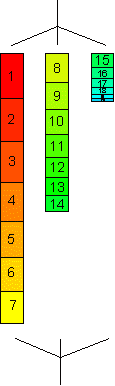
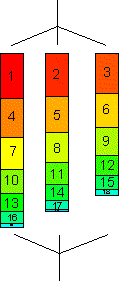
SCHEDULE(STATIC, blocksize)
partition index range in blocks of fixed length
(blocksize)
blocks are dealt out to threads in round robin way
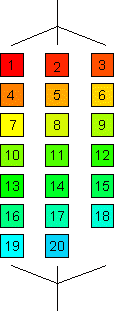
SCHEDULE(DYNAMIC, blocksize)
partition index range in blocks of fixed length
blocksize (as above)
when a thread completes a block, it gets the next one
important for loops with strongly varying times per iteration
- (even better load balancing in our example)