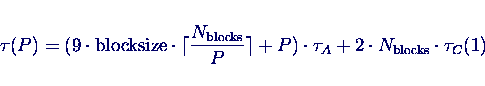neue MPI-Funktionen:
- int MPI_Gather(void *sendbuf, int sendcount, MPI_Datatype sendtype,
void *recvbuf, int recvcount, MPI_Datatype recvtype,
int root, MPI_Comm comm)
Einsammeln von verteilten Daten auf Task root
- int MPI_Get_processor_name(char *name, int *resultlength)
Name des lokalen Prozessors
Lastverteilung:
- zentrales Problem für parallele Performance
- besonders kritisch in Workstation-Clustern
- Blockgröße hier kritische Größe:
- zu klein
 hoher Kommunikations-Overhead
hoher Kommunikations-Overhead
- zu groß Zeitaufwand wird dominiert durch langsame
Prozessoren
Abschätzen der Performance:
- Annahme: gleichmäßige Verteilung der Blöcke
Modell erfaßt unterschiedliche Rechnerauslastung nicht!
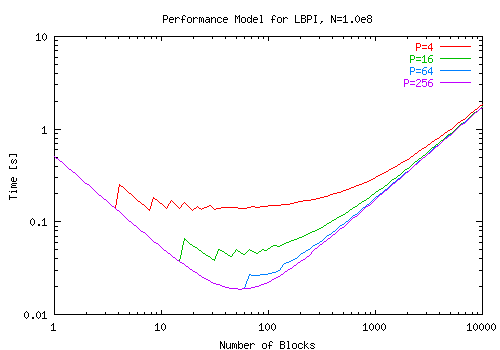
- Gesamtzeit bei konstanter Gesamtarbeit, aber verschiedener Blocksize
(d.h.
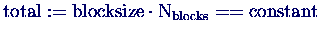 ):
):
- Zeiten auf der N-Class:




Peter Junglas 11.5.2000